Run in Postman
- Dateianforderungen
- Erforderliche Eigenschaften für das Importieren von Einträgen und Aktivitäten
- Erforderliche Eigenschaften für das Importieren von Teilnehmern an Marketingevents
Einen Import starten
Sie können einen Import starten, indem Sie einePOST-Anfrage an /crm/v3/imports durchführen, die einen Anfragetext enthält, der angibt, wie die Spalten Ihrer Importdatei den zugehörigen Eigenschaften in HubSpot zugeordnet werden sollen.
API-Importe werden als form-data-Typ-Anfragen gesendet, wobei der Anfragetext die folgenden Felder enthält:
- importRequest: Dies ist ein Textfeld, das den Anfrage-JSON enthält.
- files: Dies ist ein Dateifeld, das die Importdatei enthält.
Content-Type-Header mit dem Wert multipart/form-data hinzu.
Der folgende Screenshot zeigt, wie Ihre Anfrage bei der Verwendung einer Anwendung wie Postman aussehen könnte:
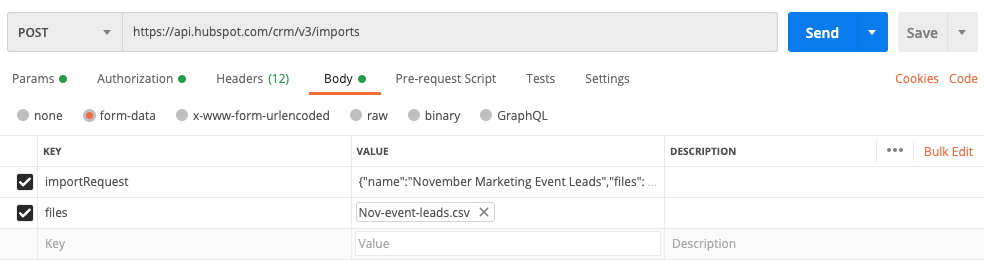
Die importRequest-Daten formatieren
Definieren Sie in Ihrer Anfrage die Details der Importdatei, einschließlich der Zuordnung der Spalten der Tabelle zu HubSpot-Daten. Ihre Anfrage sollte die folgenden Felder enthalten:- name: Dies ist der Name der Imports. In HubSpot ist dies der Name, der im Import-Tool angezeigt wird, sowie der Name, auf den Sie in anderen Tools wie Listen verweisen können.
- importOperations: Dies ist ein optionales Feld, das angibt, ob der Import für ein bestimmtes Objekt oder eine bestimmte Aktivität Datensätze erstellen und aktualisieren, sie nur erstellen oder nur aktualisieren soll. Schließen Sie die
objectTypeIdfür das Objekt / die Aktivität ein und ob Sie für Datensätze eineUPSERT-Aktion (erstellen und aktualisieren), eineCREATE-Aktion oder eineUPDATE-Aktion durchführen möchten. Zum Beispiel würde das Feld in Ihrer Anfrage wie folgt aussehen:"importOperations": {"0-1": "CREATE"}. Wenn Sie dieses Feld nicht einschließen, ist der Standardwert für den ImportUPSERT. - dateFormat: Dies ist das Format für Daten, die in der Datei berücksichtigt werden. Standardmäßig wird dieser auf
MONTH_DAY_YEARfestgelegt, aber Sie können auchDAY_MONTH_YEARoderYEAR_MONTH_DAYverwenden. - marketableContactImport: Dies ist ein optionales Feld, um den Marketingstatus von Kontakten in Ihrer Importdatei anzugeben. Es wird nur verwendet, wenn Kontakte in Accounts importiert werden, die Zugriff auf Marketingkontakte haben. Um die Kontakte in der Datei als Marketingkontakte einzustufen, verwenden Sie den Wert
true. Um die Kontakte in der Datei als Nicht-Marketingkontakte einzustufen, verwenden Sie den Wertfalse. - createContactListFromImport: Dies ist ein optionales Feld zum Erstellen einer statischen Liste der Kontakte aus Ihrem Import. Um eine Liste aus Ihrer Datei zu erstellen, verwenden Sie den Wert
true. - files: Dies ist ein Array, das Ihre Importdateiinformationen enthält.
- fileName: Dies ist der Name der Importdatei.
- fileFormat: Dies ist das Format der Importdatei. Verwenden Sie bei CSV-Dateien den Wert
CSV. Verwenden Sie bei Excel-Dateien den WertSPREADSHEET. - fileImportPage: Enthält das
columnMappings-Array, das zum Zuordnen von Daten aus Ihrer Importdatei zu HubSpot-Daten erforderlich ist. Im Folgenden erfahren Sie mehr über das Zuordnen von Spalten.
Dateispalten zu HubSpot-Eigenschaften zuordnen
Fügen Sie innerhalb descolumnMappings-Arrays einen Eintrag für jede Spalte in Ihrer Importdatei ein, der der Reihenfolge der Spaltenüberschriften Ihrer Tabelle entspricht.
Fügen Sie für jede Spalte die folgenden Felder hinzu:
- columnObjectTypeId: Dies ist der Name oder
objectTypeId-Wert des Objekts oder der Aktivität, zu dem/der die Daten gehören. Eine vollständige Liste derobjectTypeId-Werte finden Sie in diesem Artikel. - columnName: Dies ist der Name der Spaltenüberschrift. Dies sollte genau mit dem Namen der Spaltenüberschrift in der Datei übereinstimmen.
- propertyName: Dies ist der interne Name der HubSpot-Eigenschaft, welcher die Daten zugeordnet werden. Für die gemeinsame Spalte bei Importen von mehreren Dateien sollte
propertyNameden Wertnullhaben, wenn dastoColumnObjectTypeId-Feld verwendet wird. - columnType: Wird verwendet, um anzugeben, dass eine Spalte eine eindeutige ID-Eigenschaft enthält. Verwenden Sie abhängig von der Eigenschaft und dem Ziel des Imports einen der folgenden Werte:
- HUBSPOT_OBJECT_ID: Dies ist die ID eines Datensatzes. Beispielsweise kann Ihre Kontaktimportdatei eine Spalte mit der Datensatz-ID enthalten, in der die ID des Unternehmens gespeichert ist, dem die Kontakte zugeordnet werden sollen.
- HUBSPOT_ALTERNATE_ID: Dies ist eine eindeutige ID, die sich von der Datensatz-ID unterscheidet. Beispielsweise kann Ihre Kontaktimportdatei eine E-Mail-Spalte enthalten, in der die E-Mail-Adressen der Kontakte gespeichert sind.
- FLEXIBLE_ASSOCIATION_LABEL: Berücksichtigen Sie diesen Spaltentyp, um anzugeben, dass die Spalte Zuordnungslabel enthält.
- ASSOCIATION_KEYS: Fügen Sie nur für Importe mit Zuordnungen gleicher Objekte diesen Spaltentyp für die eindeutige ID der Datensätze des gleichen Objekttyps hinzu, die Sie zuordnen. Beispielsweise muss in Ihrer Anfrage für einen Kontaktzuordnungsimport die Spalte Zugeordneter Kontakt [E-Mail/Datensatz-ID] einen
columnTypevom TypASSOCIATION_KEYSaufweisen. Erfahren Sie mehr über das Einrichten Ihrer Importdatei bei einem Import mit Zuordnungen des gleichen Objekttyps.
- toColumnObjectTypeId: bei Importen mit mehreren Dateien oder mehreren Objekten der Name oder die
objectTypeIddes Objekts, zu dem die Eigenschaft Gemeinsame Spalte oder das Zuordnungslabel gehört. Fügen Sie dieses Feld für die Eigenschaft „Gemeinsame Spalte“ in die Datei des Objekts ein, zu dem die Eigenschaft nicht gehört. Wenn Sie beispielsweise Kontakte und Unternehmen in zwei Dateien mit der Kontakteigenschaft E-Mail als gemeinsame Spalte verknüpfen, fügen Sie dietoColumnObjectTypeIdfür die Spalte E-Mail in die Unternehmensdatei ein. - foreignKeyType: Gilt nur für Importe von mehreren Dateien. Die Art der Zuordnung, die die gemeinsame Spalte verwenden soll, wird durch die
associationTypeIdundassociationCategoryangegeben. Fügen Sie dieses Feld für die Eigenschaft „Gemeinsame Spalte“ in die Datei des Objekts ein, zu dem die Eigenschaft nicht gehört. Wenn Sie beispielsweise Kontakte und Unternehmen in zwei Dateien mit der Kontakteigenschaft E-Mail als gemeinsame Spalte verknüpfen, fügen Sie dieforeignKeyTypefür die Spalte E-Mail in die Unternehmensdatei ein. - associationIdentifierColumn: Gilt nur für Importe von mehreren Dateien. Gibt die Eigenschaft an, die in der gemeinsamen Spalte zum Zuordnen der Datensätze verwendet wird. Fügen Sie dieses Feld für die Eigenschaft „Gemeinsame Spalte“ in die Datei des Objekts ein, zu dem die Eigenschaft gehört. Wenn Sie beispielsweise Kontakte und Unternehmen in zwei Dateien mit der Kontakteigenschaft E-Mail als gemeinsame Spalte verknüpfen, legen Sie die
associationIdentifierColumnalstruefür die Spalte E-Mail in der Kontaktdatei fest.
Eine Datei mit einem Objekt importieren
Nachfolgend finden Sie ein Beispiel für einen Anfragetext für das Importieren einer Datei, um Kontakte zu erstellen:- JSON
Eine Datei mit mehreren Objekten importieren
Nachfolgend finden Sie einen Beispiel-Anfragetext für das Importieren und Zuordnen von Kontakten und Unternehmen in einer Datei mit Zuordnungslabeln:- JSON
Mehrere Dateien importieren
Nachfolgend finden Sie ein Beispiel für einen Anfragetext für das Importieren und Zuordnen von Kontakten und Unternehmen in zwei Dateien, wobei die Kontakteigenschaft E-Mail die gemeinsame Spalte in den Dateien ist:- JSON
importId, mit der Sie den Import abrufen oder abbrechen können. Nach Abschluss können Sie den Import in HubSpot anzeigen. Über API abgeschlossene Importe sind jedoch nicht als Option verfügbar, wenn Sie Datensätze nach Import in Ansichten, Listen, Berichten oder Workflows filtern.
Vorherige Importe abrufen
Um alle Importe von Ihrem HubSpot-Account abzurufen, führen Sie eineGET-Anfrage an /crm/v3/imports/ durch. Um Informationen für einen bestimmten Import abzurufen, führen Sie eine GET-Anfrage an /crm/v3/imports/{importId} durch.
Wenn Sie Importe abrufen, werden Informationen zurückgegeben, einschließlich des Namens, der Quelle, des Dateiformats, der Sprache, des Datumsformats und der Spaltenzuordnungen des Imports. Der state des Imports wird ebenfalls zurückgegeben, was eine der folgenden Optionen sein kann:
STARTED: HubSpot erkennt, dass der Import vorhanden ist, der Import hat jedoch noch nicht mit der Verarbeitung begonnen.PROCESSING: Der Import wird aktiv verarbeitet.DONE: Der Import ist abgeschlossen. Alle Objekte, Aktivitäten oder Zuordnungen wurden aktualisiert oder erstellt.FAILED: Es liegt ein Fehler vor, der beim Starten des Imports nicht erkannt wurde. Der Import wurde nicht abgeschlossen.CANCELED: Der Benutzer hat den Export abgebrochen, während er sich in einem der ZuständeSTARTED,PROCESSINGoderDEFERREDbefand.DEFERRED: Die maximale Anzahl von Importen (drei) wird gleichzeitig verarbeitet. Der Import wird gestartet, sobald einer der anderen Importe die Verarbeitung abgeschlossen hat.
Einen Import abbrechen
Um einen aktiven Import abzubrechen, führen Sie einePOST-Anfrage an /crm/v3/imports/{importId}/cancel durch.
Importfehler überprüfen und beheben
Um Fehler für einen bestimmten Import anzuzeigen, führen Sie eineGET-Anfrage an /crm/v3/imports/{importId}/errors durch. Erfahren Sie mehr über häufige Importfehler und wie Sie diese beheben können.
Bei Fehlern wie Falsche Spaltenanzahl, Unable to parse JSON oder 404 text/html is not accepted:
- Stellen Sie sicher, dass für jede Spalte in Ihrer Datei eine Spaltenüberschrift vorhanden ist und dass die Anfragetext einen
columnMapping-Eintrag für jede Spalte enthält. Folgende Kriterien müssen erfüllt sein:- Die Spaltenreihenfolge im Anfragetext und in der Importdatei muss übereinstimmen. Wenn die Spaltenreihenfolge nicht übereinstimmt, versucht das System eine automatische Neuanordnung, was jedoch möglicherweise nicht gelingt und dadurch zu einem Fehler beim Start des Imports führt.
- Jede Spalte muss zugeordnet werden. Wenn eine Spalte nicht zugeordnet ist, ist die Importanfrage zwar trotzdem erfolgreich, führt jedoch zu einem Fehler vom Typ Falsche Spaltenanzahl, wenn der Import gestartet wird.
- Stellen Sie sicher, dass der Dateiname und das
fileName-Feld in Ihrem Anfrage-JSON übereinstimmen und dass Sie die Dateierweiterung imfileName-Feld berücksichtigt haben. Zum Beispiel import_name.csv. - Stellen Sie sicher, dass Ihr Header
Content-Typemit dem Wertmultipart/form-dataenthält.